Introduction
BACKGROUND 1: FEATURE RECOVERY
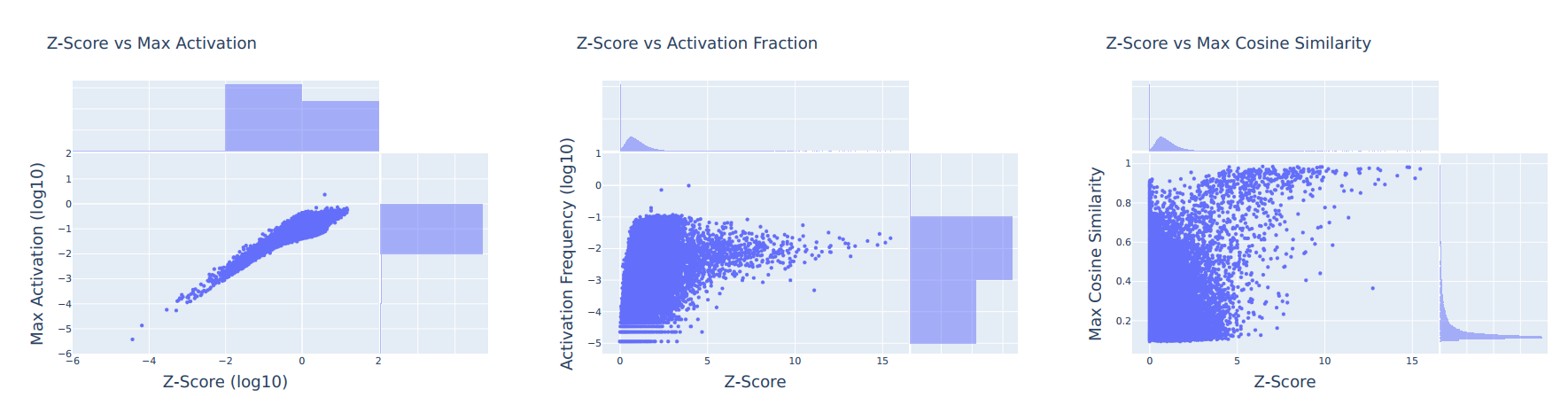
To understand the task of feature recovery, let us consider the following example sentence:The sentence contains two distinct concepts: a muddy footprint and a broken window. For a trained deep neural network, the learned representations in the intermediate layers are often polysemantic, meaning that they are mixture of multiple features of the underlying concepts. Specifically, the representation \(x\) after seeing the whole sentence may have the following form:The detective found a muddy footprint near the broken window, leading him to suspect a ?
\(x = h_1 \cdot\) "feature of muddy footprint" \( + h_2 \cdot\) "feature of broken window"where \(h_1\) and \(h_2\) are the nonnegative weights of the two monosemantic features. After obtaining the polysemantic representation \(x\), the model can then generate the token "burglary" at the "?" position.
The goal of feature recovery is to recover the monosemantic features underlying each concept, through training on a dataset that contains polysemantic representations, which are often extracted from the intermediate layers of a trained deep neural network, e.g., the residual stream of a transformer-based model.While this example illustrates the intuitive notion of monosemantic features, we need a more rigorous definition to make progress. Currently, researchers primarily assess monosemanticity through feature interpretability, i.e., how well a feature aligns with human-understandable concepts. However, this anthropocentric view has limitations: neural networks may process information in ways fundamentally different from human conceptual understanding. We need a more principled, mathematically grounded definition of monosemantic features that captures their essential properties independent of human interpretation. Specifically, we ask the following questions:
Question 1
What is a mathematically rigorous definition of identifiable monosemantic features?
Question 2
Given polysemantic representations, when will the monosemantic features be identifiable?
Question 3
How to reliably recover the monosemantic features?
BACKGROUND 2: SPARSE AUTOENCODERS
📚 What are SAEs?
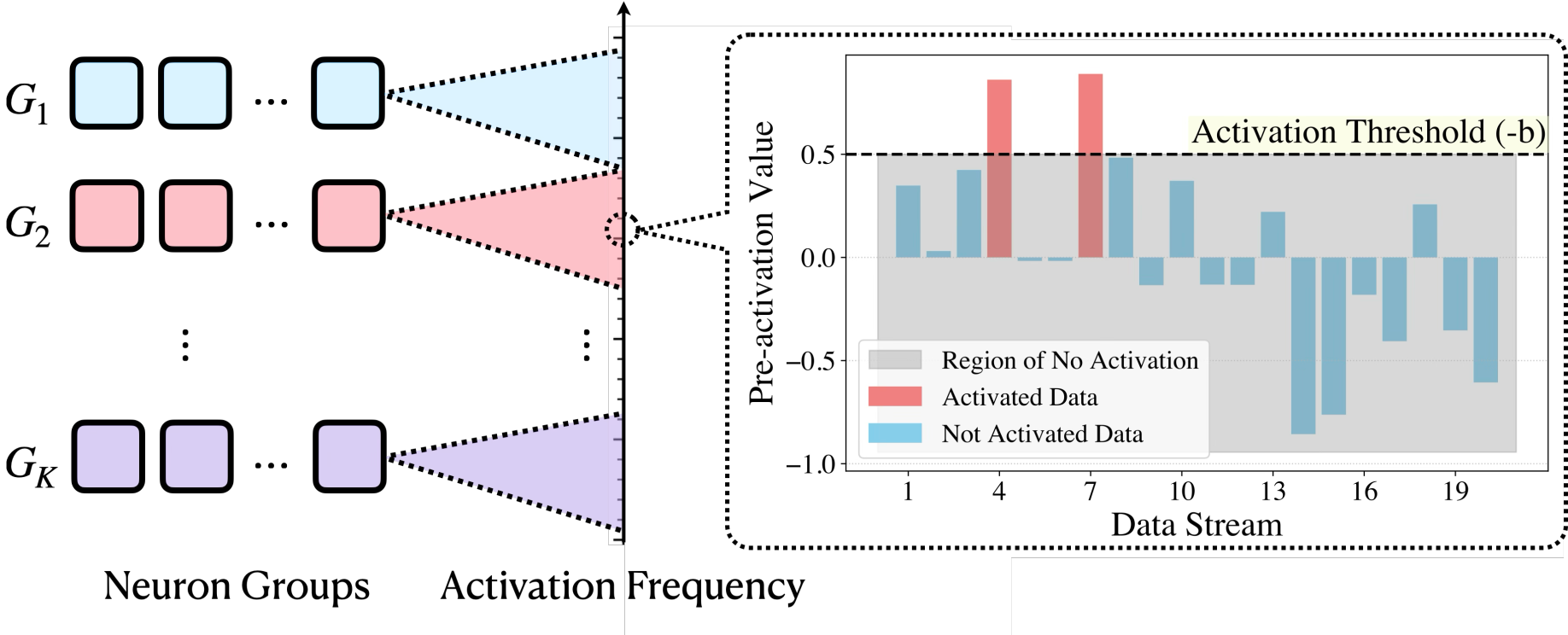
At the core of our feature recovery method is the Sparse Autoencoder (SAE), a neural network designed to learn sparse representations through self-reconstruction. A typical SAE architecture (with weight sharing between encoding and decoding layers) can be described as follows: \[ \hat x = \sum_{m=1}^M a_{m} \cdot w_{m} \cdot \phi\bigl( \underbrace{{w_{m}^\top (x-b_{\mathrm{pre}}) + b_{m}}}_{\displaystyle \small\text{pre-activation}~y_m} \bigr) + b_{\mathrm{pre}}, \] where each \(m\) index a neuron in the SAE, \(w_m\in \mathbb{R}^d\) is the tied weight vector for both encoding and decoding, \(a_m\in \mathbb{R}\) is the output scale for neuron \(m\), \(b_m\in \mathbb{R}\) is the bias for neuron \(m\), and \(b_{\mathrm{pre}}\in \mathbb{R}^d\) is the pre-bias vector that centers the input data. People usually use some nonlinear activation function \(\phi\) like ReLU or JumpReLU.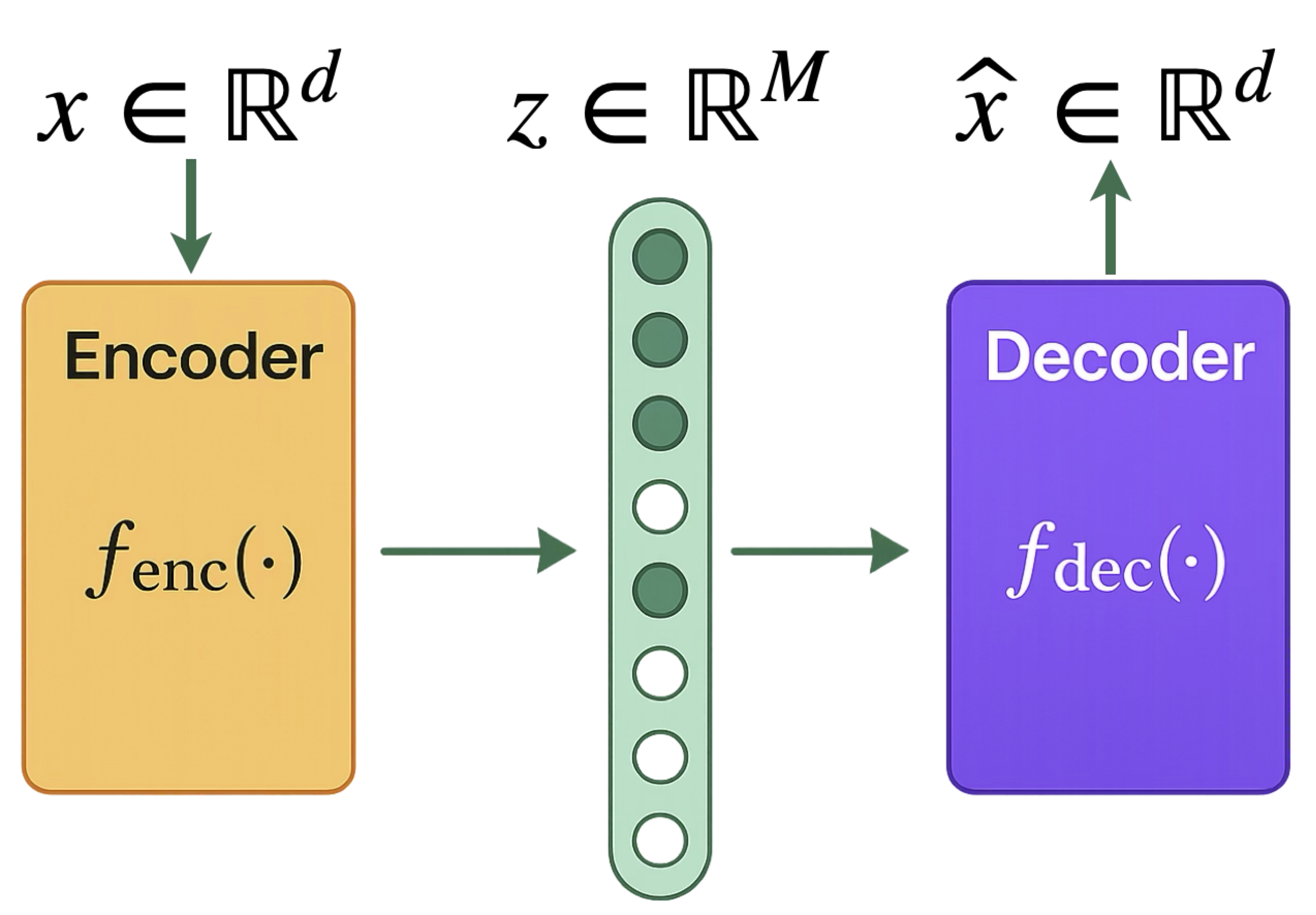
🔧 How are SAEs trained?
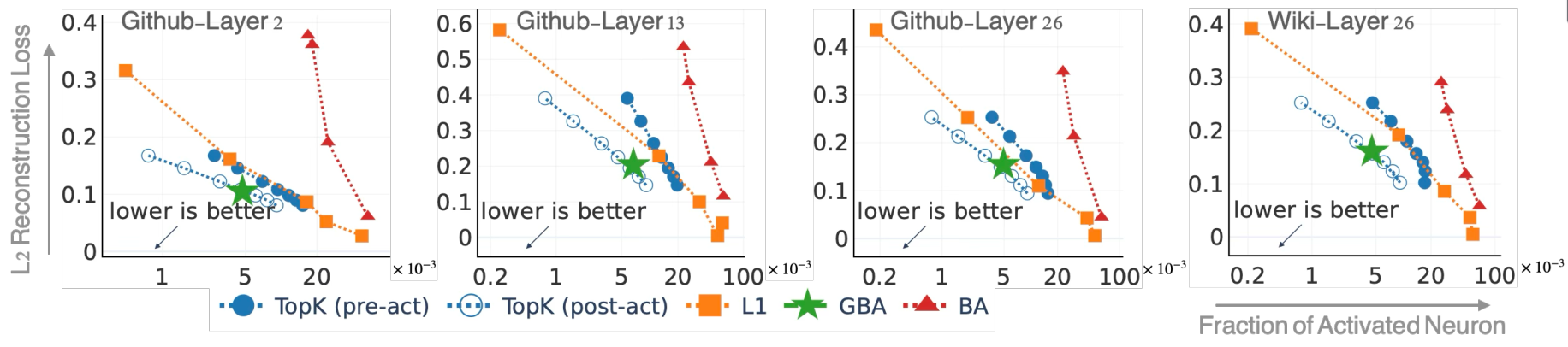
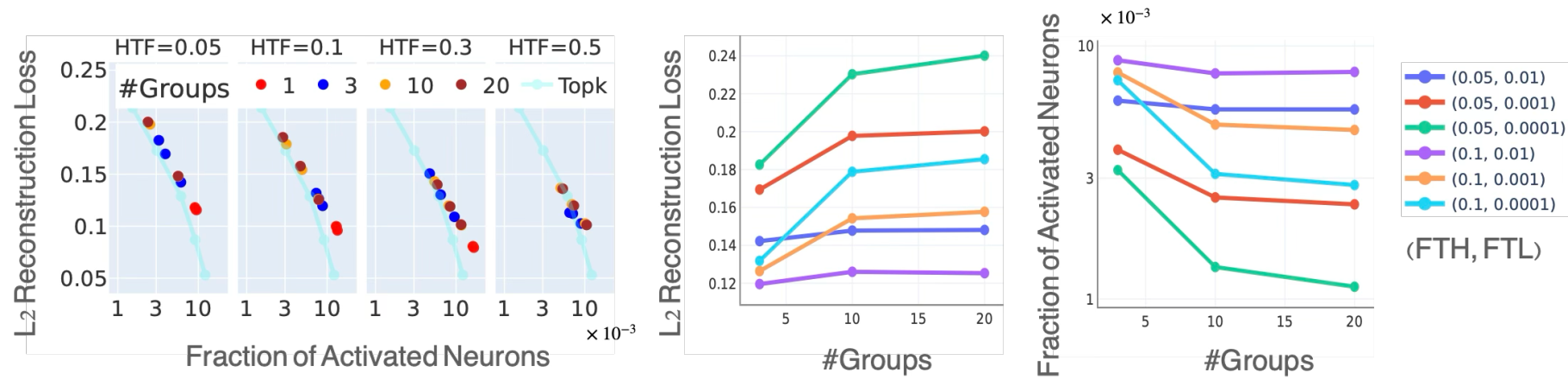
Given the input \(x\in \mathbb{R}^d\), the SAE outputs \(\hat x\in \mathbb{R}^d\) as the reconstruction, and the training objective is to minimize the reconstruction error with a regularization term to encourage sparsity. Specifically, the training objective for the \(\ell_1\) method is to minimize the following loss function: \[ \mathcal{L} = \mathbb{E}_{x\sim \mathcal{D}} \biggl[\underbrace{ (\hat x - x)^2}_{\displaystyle \small\text{reconstruction loss}} + \underbrace{\lambda \sum_{m=1}^M \|w_m\|_2 \phi(w_m^\top (x - b_{\mathrm{pre}}) + b_m)}_{\displaystyle \small\text{sparsity regularization}} \biggr]. \] where \(\mathcal{D}\) is the training dataset, and \(\lambda\) is the regularization parameter. The first term is the reconstruction loss, and the second term is the sparsity regularization term. The sparsity regularization term encourages the SAE to activate only a small number of neurons, which is crucial for feature recovery. The TopK method does not have a regularization term, and the activation frequency is controlled by only allowing the top-K neurons in terms of the pre-activation \(y_m\) to be activated.🤔 Why using SAEs?
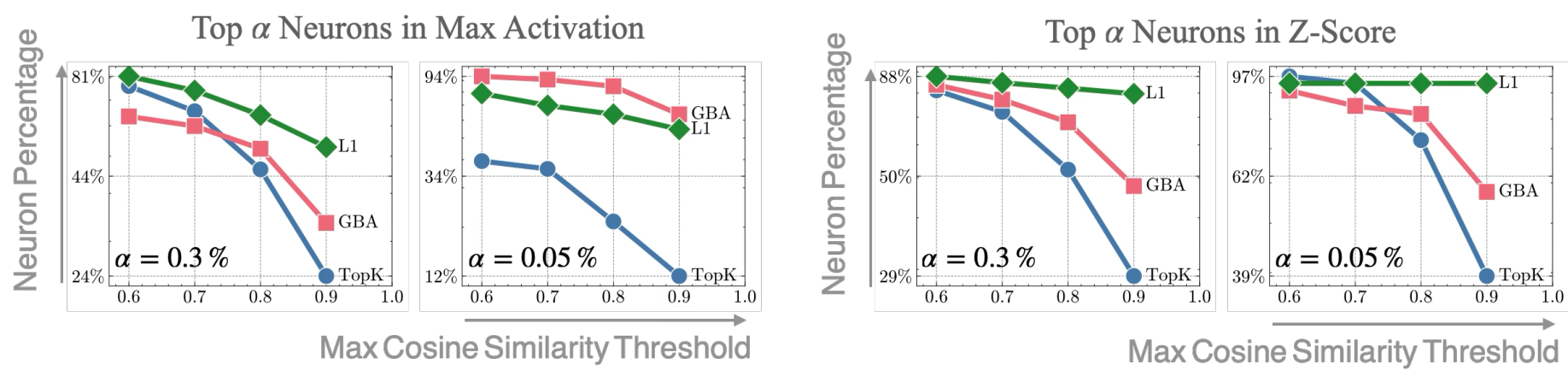
The hypothesis is that by enforcing activation sparsity, SAEs can decompose polysemantic representations (a mixture of multiple features) into monosemantic features (which each correspond to a single interpretable concept). Empirically, SAEs have been shown to learn interpretable features for LLMs.
WHAT ARE THE CHALLENGES
The current SAE training algorithms face the following challenges:- Theoretical uncertainty: We lack clear feature definitions and current SAE training algorithms lack theoretical guarantees, making reliable feature recovery uncertain.
- Hyperparameter sensitivity: Empirically, \( \ell_1 \) regularization and TopK activation methods are sensitive to hyperparameters tuning.
- Feature inconsistency: TopK activation methods produce inconsistent features across different random seeds.1
WHAT ARE OUR GOALS
Our research aims to address these challenges with the following objectives:- Theoretical foundation: Develop a rigorous mathematical framework for understanding and analyzing feature recovery in SAEs.
- Algorithm design: Create a simple and robust training algorithm that can reliably recover monosemantic features without extensive hyperparameter tuning, and learn more consistent features across different random seeds.
1Paulo, Gonçalo, and Nora Belrose. "Sparse Autoencoders Trained on the Same Data Learn Different Features." https://arxiv.org/abs/2501.16615
2Chris Olah. "Interpretability Dreams." https://transformer-circuits.pub/2023/interpretability-dreams/index.html