INFUSER: Influence-Guided Self-Evolution Improves Reasoning
AUTHORS: Siyu Chen, Miao Lu, Beining Wu, Heejune Sheen, Fengzhuo Zhang, Shuangning Li, Zhiyuan Li, Jose Blanchet, Tianhao Wang, and Zhuoran Yang.
TL;DR
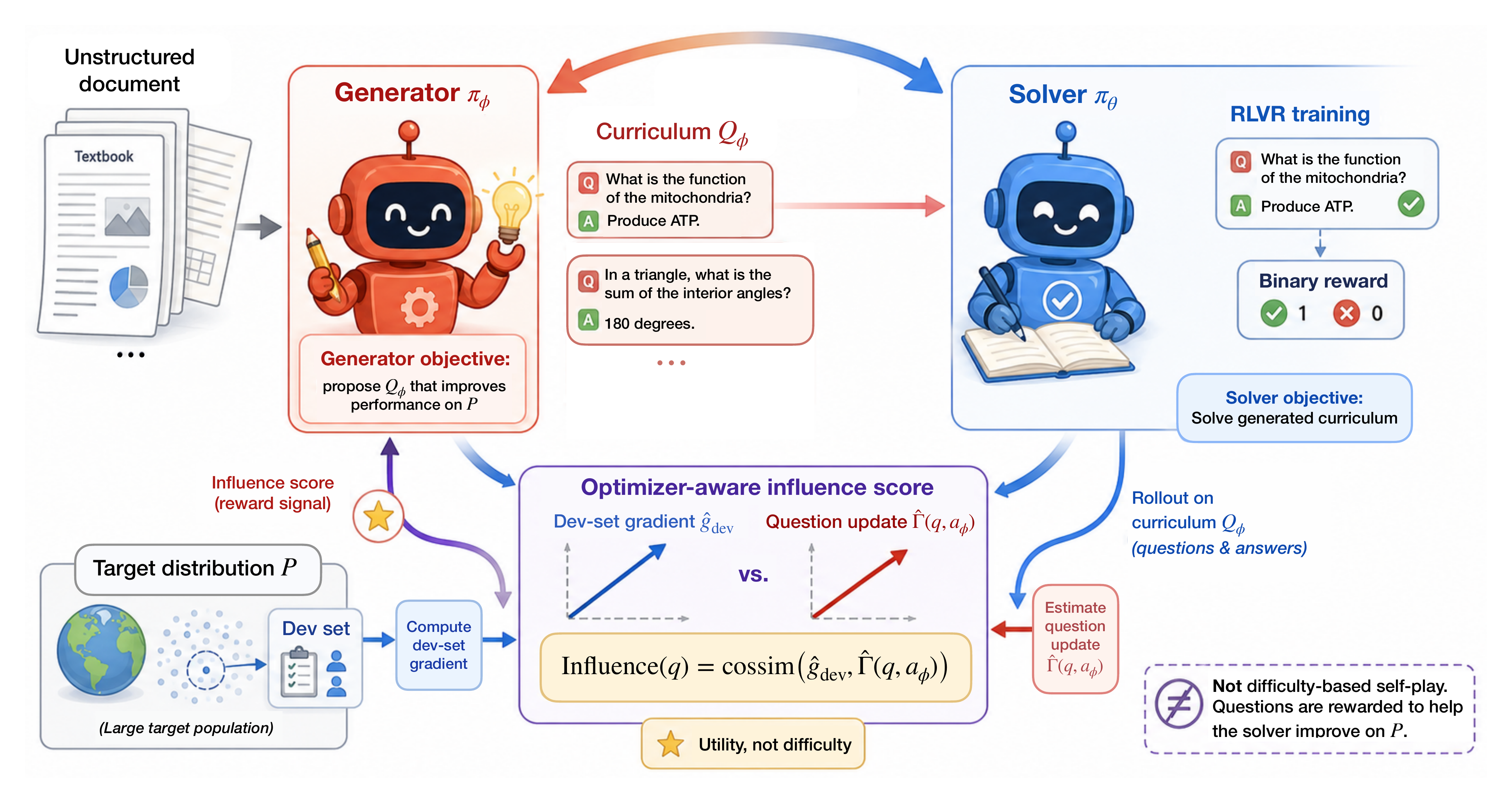
Self-improvement depends on whether a pretrained model can self-generate curriculum that is both challenging and useful. INFUSER views this as a bilevel optimization problem and turns self-evolution into influence-guided curriculum learning. A co-evolving generator drafts questions and reference answers from unstructured documents, while a solver trains on them with correctness rewards. Instead of rewarding the generator for surface difficulty, INFUSER rewards each generated question by an optimizer-aware influence score: would training on this example move the solver toward the capabilities we want to improve?
This continuous and noisy influence reward is optimized with DuGRPO, a dual-normalized GRPO variant for generator training. Together, the generator, solver, and influence estimator turn a document pool into an adaptive curriculum that favors questions useful to the current solver, not merely harder ones.
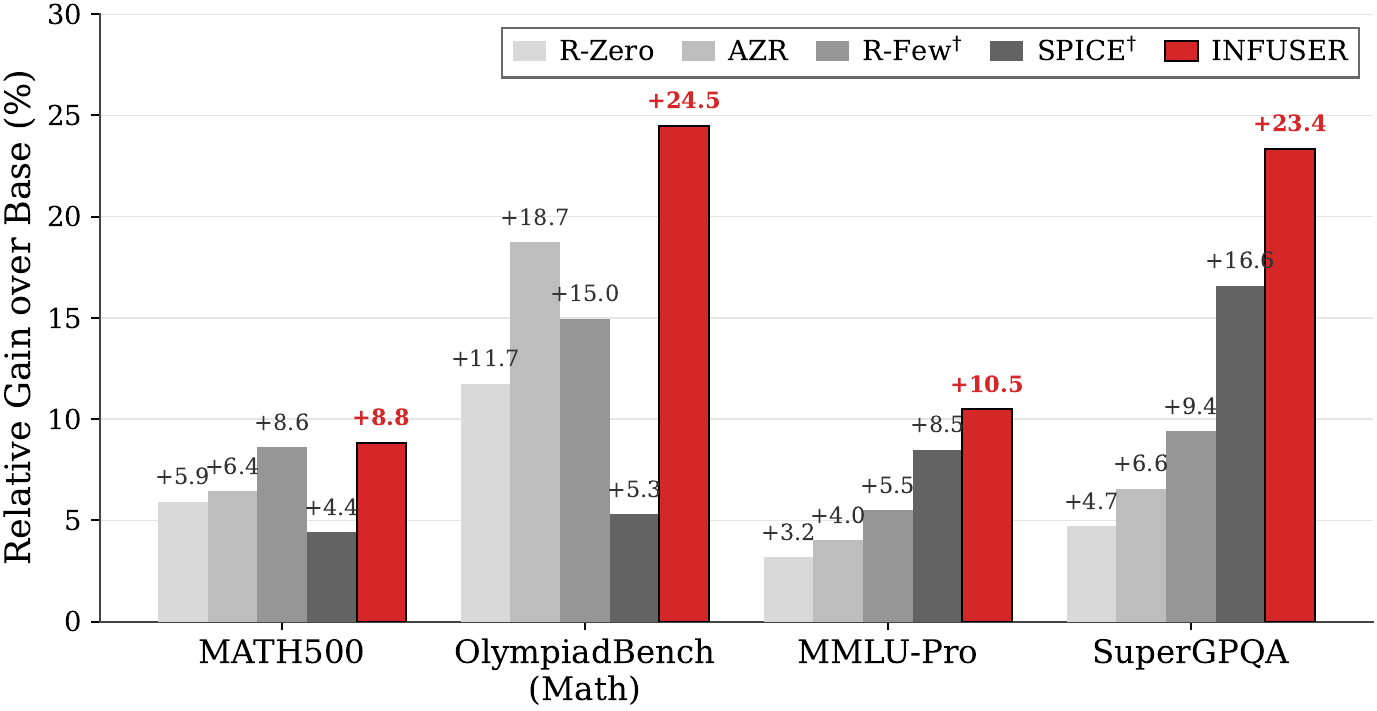
On Qwen3-8B-Base, INFUSER outperforms strong self-evolution baselines, including over 20% relative improvement on Olympiad and SuperGPQA benchmarks. Its 8B co-evolving generator also outperforms a frozen 32B thinking generator on math and coding, while ablations confirm the importance of optimizer-aware influence and DuGRPO.
1. From Documents to Useful RL Signals
RLVR is powerful because it can train a solver from verifiable rewards, but it does not by itself solve the data problem. A textbook, paper, or web document may contain useful knowledge, yet an unstructured document does not directly provide the structured question, reference answer, and reward signal that RLVR consumes.
This is why self-evolution needs a generator: the generator converts raw documents into a curriculum of question-answer pairs, and the solver trains on that curriculum with RL. The remaining question is how to train the generator itself. If the generated data is heavily curated or teacher-generated, the system inherits the cost and bias of that teacher. If the generator is trained only by proxy signals, the most common proxy is difficulty against the current solver, as in recent self-evolution systems such as R-Zero and SPICE.
The problem: difficulty is not the same thing as usefulness. A generator can produce mislabeled or invalid questions that look difficult, but these examples can harm training. Even when the generator poses valid questions, it is hard to know whether they are relevant to what we want the solver to improve on.
INFUSER replaces this heuristic with a utility signal: reward generated questions whose induced solver-gradient direction is useful for the dev-set objective.
2. INFUSER: Training for Usefulness
INFUSER has three coupled roles:
- Generator \(\pi_\phi\): reads documents from a corpus and drafts a curriculum \(\mathcal{Q}_\phi\) of question-answer pairs \((q, a_\phi)\).
- Solver \(\pi_\theta\): answers generated questions and improves by RL training against the generated reference answers.
- Influence estimator: scores each generated pair by how useful its solver update is for performance on the held-out development set (dev-set).
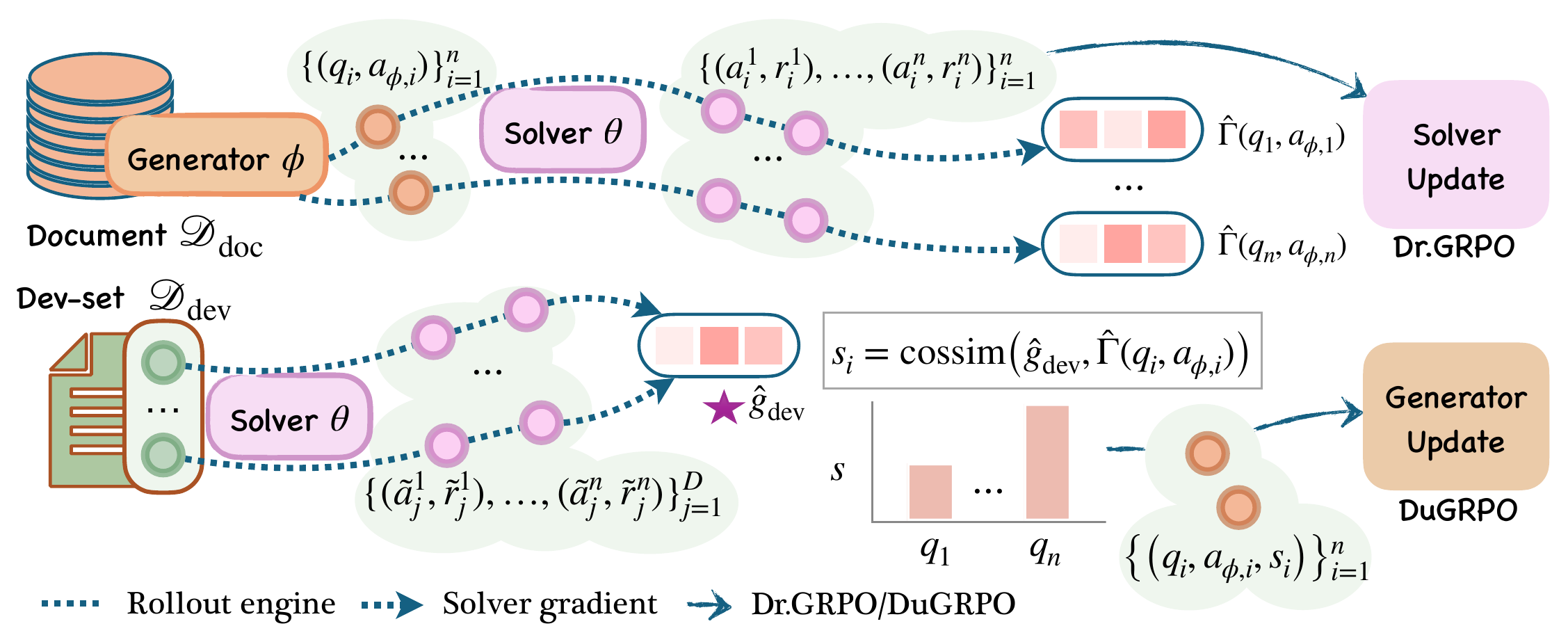
At each iteration, INFUSER estimates a solver-side development reference gradient \(\hat g_{\mathrm{dev}}\) as an RL gradient of the current solver on a fixed dev-set. This gradient encodes the question:
If the solver wants to improve on the dev-set, which direction should it move in parameter space?
For each generated pair \((q, a_\phi)\), INFUSER asks the solver to sample rollouts on \(q\) and uses the generated answer \(a_\phi\) as the reference for solver-side RL rewards. From those rollouts, INFUSER estimates the solver-side optimizer-aware RL update direction \(\hat\Gamma(q, a_\phi)\). This direction encodes the question:
If the solver trains on this generated question, which direction would the optimizer move it?
The influence reward is the cosine similarity
$$ \hat s(q, a_\phi) = \mathrm{cossim}\bigl(\hat g_{\mathrm{dev}}, \hat\Gamma(q, a_\phi)\bigr). $$A large cosine similarity indicates that training on the generated question would move the solver in a direction aligned with dev-set improvement. A low or negative similarity indicates that the question is unhelpful or potentially harmful for the dev-set objective we want the solver to improve on.
The generator is updated using this influence reward. The solver is updated using correctness rewards on the same generated questions. Because the influence reward is continuous and noisy, INFUSER trains the generator with DuGRPO, a dual-normalized variant of GRPO designed to stabilize this setting. In DuGRPO, the generator advantage is computed as
$$ \hat A_{\mathrm{gen}}(q^k, a_{\phi}^k) = \frac{\hat s(q^k, a_{\phi}^k)-\mu_d} {\sigma_d+\sigma_{\mathcal{B}}+\epsilon}. $$Here, \(\mu_d\) and \(\sigma_d\) are the mean and standard deviation of influence rewards for questions generated from the same document \(d\), while \(\sigma_{\mathcal{B}}\) is the average group standard deviation across the document batch. Unlike standard GRPO, the extra \(\sigma_{\mathcal{B}}\) term avoids amplifying noise in low-variance groups, while still preserving useful within-document ranking.
3. INFUSER from the View of Bilevel Optimization
After the influence-score view, the deeper way to understand INFUSER is as a bilevel optimization problem. The generator does not merely emit data; it chooses a curriculum \(\mathcal{Q}_\phi\). The solver then learns on that curriculum, and the generator is judged by how well the resulting solver performs on the dev-set.
For this discussion, define the performance of a solver on any question-answer distribution \(\mathcal{D}\) as
$$ J_{\mathcal{D}}(\theta) = \mathbb{E}_{(q,a)\sim\mathcal{D},\;a'\sim\pi_\theta(\cdot\mid q)} \bigl[r(a',a)\bigr]. $$Let \(\mathcal{D}_{\mathrm{dev}}\) denote the held-out dev-set. Then the bilevel objective asks the generator to choose a curriculum \(\mathcal{Q}_\phi\) such that, after the solver trains on that curriculum, the resulting solver performs well on \(\mathcal{D}_{\mathrm{dev}}\):
$$ \max_\phi\; J_{\mathcal{D}_{\mathrm{dev}}}\!\bigl(\theta^*(\phi)\bigr), \qquad \theta^*(\phi) = \arg\max_\theta J_{\mathcal{Q}_\phi}(\theta). $$The lower level asks: if the generator fixed its curriculum \(\mathcal{Q}_\phi\), what solver would we get after training on it? The upper level asks: did that trained solver improve on the dev-set? This is why the generator is optimized for usefulness rather than difficulty.
The solver learns from the curriculum; the generator learns which curriculum helps the solver.
Exact bilevel optimization would require retraining the solver to convergence for every generator update, which is infeasible for LLMs. INFUSER therefore takes a local view: replace \(\theta^*(\phi)\) with the parameter after one optimizer step with respect to \(J_{\mathcal{Q}_\phi}\). To see the resulting tractable signal, start with the simpler SGD case. Let \(\hat g(q,a_\phi)\) denote the per-question RL gradient induced by training on the generated pair \((q,a_\phi)\). If the solver takes one SGD step on the generated curriculum \(\mathcal{Q}_\phi\), the resulting dev-set improvement decomposes over questions:
$$ J_{\mathcal{D}_{\mathrm{dev}}}\!\bigl(\theta_t+\Delta\theta_{\mathrm{SGD}}(\mathcal{Q}_\phi)\bigr) - J_{\mathcal{D}_{\mathrm{dev}}}(\theta_t) \approx \frac{\eta_s}{|\mathcal{Q}_\phi|} \sum_{(q,a_\phi)\in\mathcal{Q}_\phi} \langle \hat g_{\mathrm{dev}}, \hat g(q,a_\phi) \rangle. $$This gives a per-question contribution: questions whose solver-side RL gradient aligns with \(\hat g_{\mathrm{dev}}\) are useful for the dev-set objective. Therefore, optimizing \(J_{\mathcal{D}_{\mathrm{dev}}}\bigl(\theta_t+\Delta\theta_{\mathrm{SGD}}(\mathcal{Q}_\phi)\bigr)\) is equivalent to optimizing the average inner-product term, which means we can treat that inner product as the generator reward and apply RL optimization. INFUSER applies the same idea by replacing the raw solver-side SGD gradient \(\hat g(q,a_\phi)\) with the solver-side optimizer-aware RL update direction \(\hat\Gamma(q,a_\phi)\):
$$ \hat s(q,a_\phi) = \mathrm{cossim}\bigl(\hat g_{\mathrm{dev}}, \hat\Gamma(q,a_\phi)\bigr). $$Using cosine similarity keeps the reward focused on update direction and avoids spurious effects from sequence length or gradient norm. Since both the generator and solver objectives are now formulated as RL optimization problems, INFUSER optimizes them with alternating iterative updates.
In short: documents provide knowledge, the dev-set provides direction, and influence-guided RL for the generator connects the two into an adaptive curriculum.
4. Main Results
Across both Qwen3-4B-Base and Qwen3-8B-Base anchors, INFUSER improves the base model on the four headline benchmarks. Relative gains over the corresponding base model are shown in parentheses.
| Benchmark | 4B Base | 4B INFUSER | 8B Base | 8B INFUSER |
|---|---|---|---|---|
| MATH500 | 61.20 | 76.65(+25.2%) | 76.05 | 82.77(+8.8%) |
| OlympiadBench (Math) | 35.31 | 42.38(+20.0%) | 40.36 | 50.24(+24.5%) |
| MMLU-Pro | 52.98 | 60.20(+13.6%) | 59.91 | 66.20(+10.5%) |
| SuperGPQA | 25.88 | 33.48(+29.4%) | 30.62 | 37.77(+23.4%) |
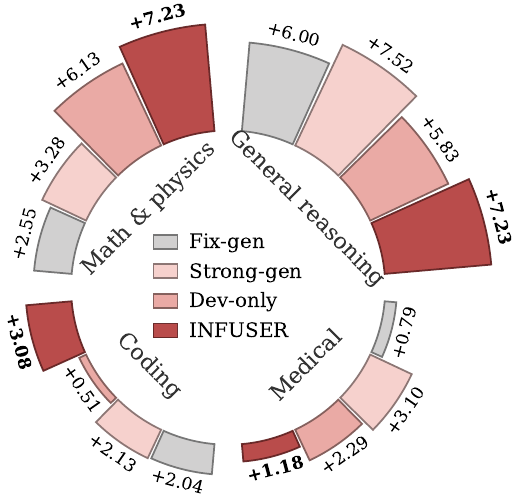
Across the full benchmark suite, INFUSER's strongest gains appear on domains aligned with the document pool and dev-set, while still giving positive transfer on medical and coding benchmarks:
| Category Average | Qwen3-4B-Base | Qwen3-8B-Base | ||||||
|---|---|---|---|---|---|---|---|---|
| Base | R-Zero | AZR | INFUSER | Base | R-Zero | AZR | INFUSER | |
| General reasoning | 29.46 | 32.18 | 32.93 | 35.43(+20.3%) | 34.43 | 37.14 | 37.61 | 40.62(+18.0%) |
| Math & physics | 21.34 | 25.12 | 26.51 | 25.73(+20.6%) | 26.08 | 28.46 | 30.28 | 31.49(+20.7%) |
| Medical (OOD) | 34.24 | 36.75 | 36.14 | 36.32(+6.1%) | 39.34 | 40.17 | 39.89 | 40.52(+3.0%) |
| Coding (OOD) | 45.47 | 47.65 | 47.49 | 48.63(+6.9%) | 50.59 | 52.55 | 53.18 | 53.29(+5.3%) |
| Avg | 32.63 | 35.43 | 35.77 | 36.53(+12.0%) | 37.61 | 39.58 | 40.24 | 41.48(+10.3%) |
1. Aligned domains move the most. General reasoning and math & physics are closest to the science document pool and dev-set, and both anchors see roughly 20% relative gains there.
2. The gains transfer out of domain. Even though medical and coding are OOD for the training signal, INFUSER still improves over the base model on both categories.
3. The recipe scales to 8B. At 8B, INFUSER leads on all four category averages, and its 4B-to-8B gain decay is smaller than competing self-evolution baselines.
5. Results Analysis
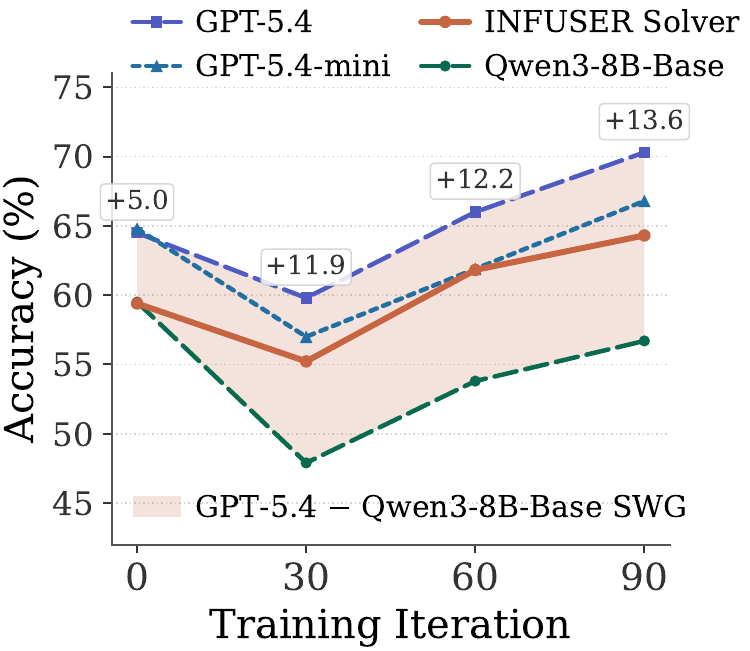
The Generator Actually Improves
The generator-quality plot asks whether the generator is really improving, or merely drifting toward noisy hard-looking questions. We evaluate questions produced at different training iterations with three types of solvers:
- Fixed Qwen3-8B-Base solver. If the trained generator produces harder questions than the initial generator, this fixed base solver should solve fewer of them.
- GPT-5.4 / GPT-5.4-mini reference solvers. If question quality improves, with fewer invalid or ill-posed questions, strong solvers should solve more of them.
- Co-trained INFUSER solver. This shows how our trained solver reacts to the rising curriculum produced by its co-evolving generator.
The key signal is the strong-against-weak gap (SWG): if GPT-5.4 improves relative to the fixed base solver, the questions are becoming harder for the base model while remaining answerable by a stronger solver.
The curve shows this rising-curriculum behavior. From iteration 0 to 30, accuracy drops, but the strong-against-weak gap more than doubles. From iteration 30 to 90, both solver accuracies rise, while GPT-5.4 rises faster and the gap widens further. Meanwhile, the INFUSER solver stays above the base model and tracks GPT-5.4-mini, indicating that the co-evolving solver is learning from the generator's increasingly useful curriculum. This suggests that the added difficulty reflects genuine reasoning challenge rather than invalid questions.
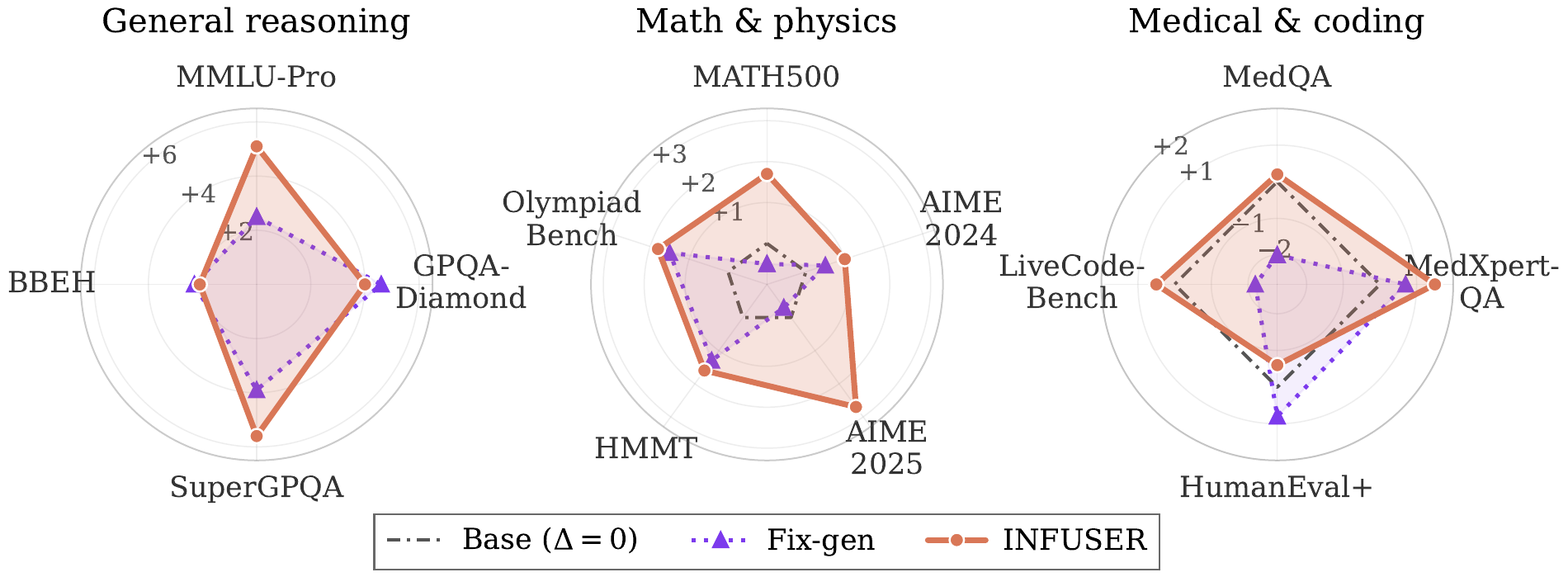
Ablations
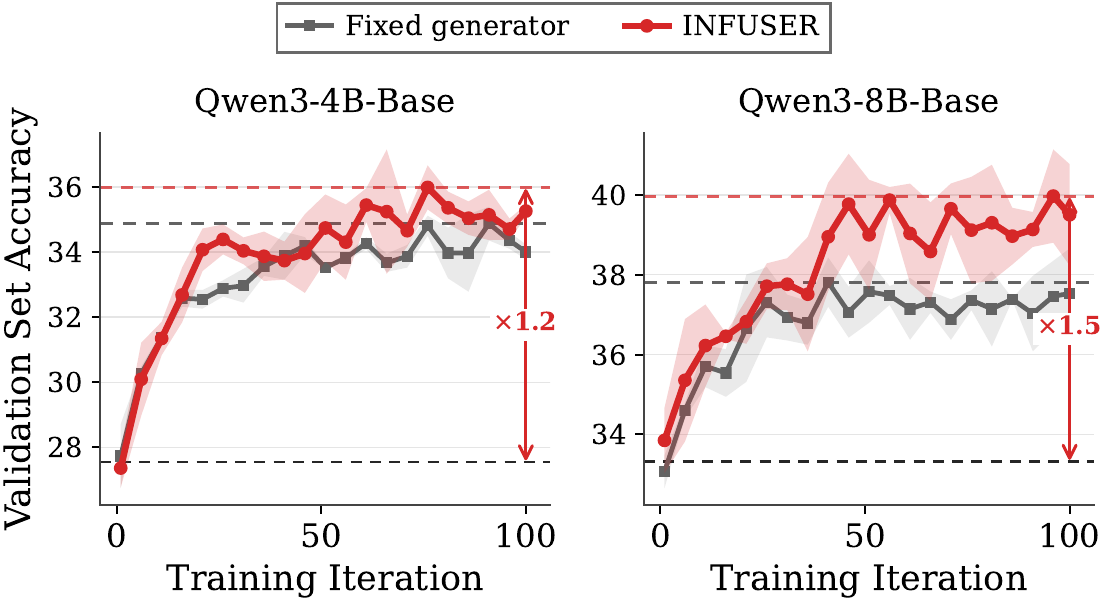
- A fixed generator trails INFUSER, showing that co-evolution matters.
- A larger frozen 32B generator helps on some knowledge-heavy domains, but INFUSER's 8B co-evolving generator remains stronger on math and coding.
- RLVR on the dev-set (Dev-only) improves the base model, but is narrower than influence-guided document generation.
- Optimizer-aware influence and DuGRPO normalization are important for stable generator learning.
6. Extensions
The main experiments start from pretrained Qwen3 base models and use only document-grounded self-evolution. The paper also tests two extensions that ask whether the same idea survives more realistic or mixed training settings.
Instruction-Finetuned Anchor
INFUSER still helps when the anchor has already been instruction-finetuned. On OLMo-3-7B-Instruct-SFT, INFUSER leads on 10 of 13 benchmarks compared with the instruction-finetuned base and a fixed-generator baseline, and it reaches the best overall average among the three variants. The gains are strongest on general reasoning, including +5.1 points on MMLU-Pro and +5.6 points on SuperGPQA, while the same aligned-domain pattern from the Qwen3 base experiments reappears.
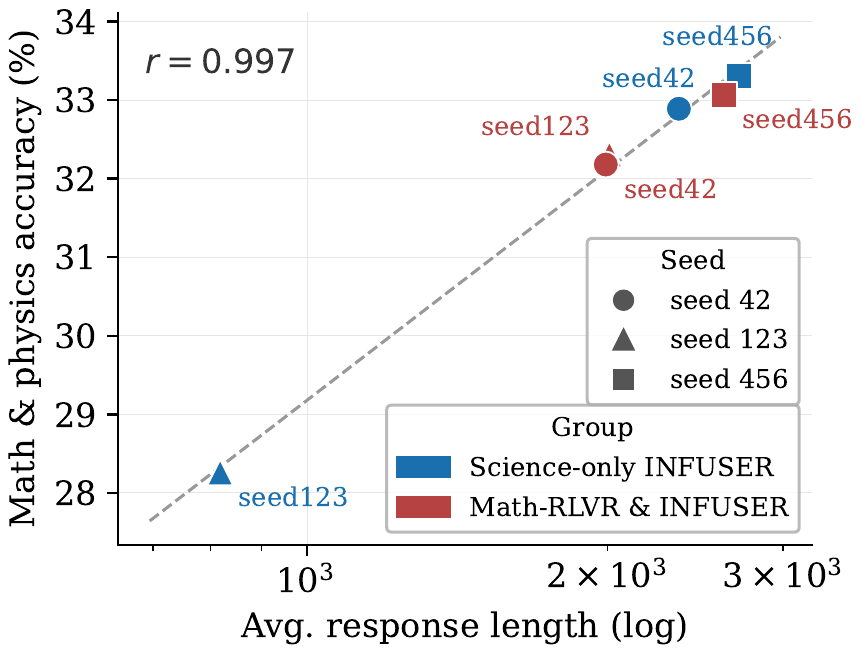
Math-RLVR Augmentation
INFUSER can also combine document-grounded science self-evolution with rule-verifiable math RLVR in a single loop. In the science-only setting, math performance is seed-sensitive because different seeds learn different response-length regimes. Adding verifiable math RLVR anchors long-CoT behavior: the math-and-physics cross-seed standard deviation drops from 2.80 to 0.48 percentage points, while the mean rises from 31.49 to 32.52.
7. More Than Best-of-k
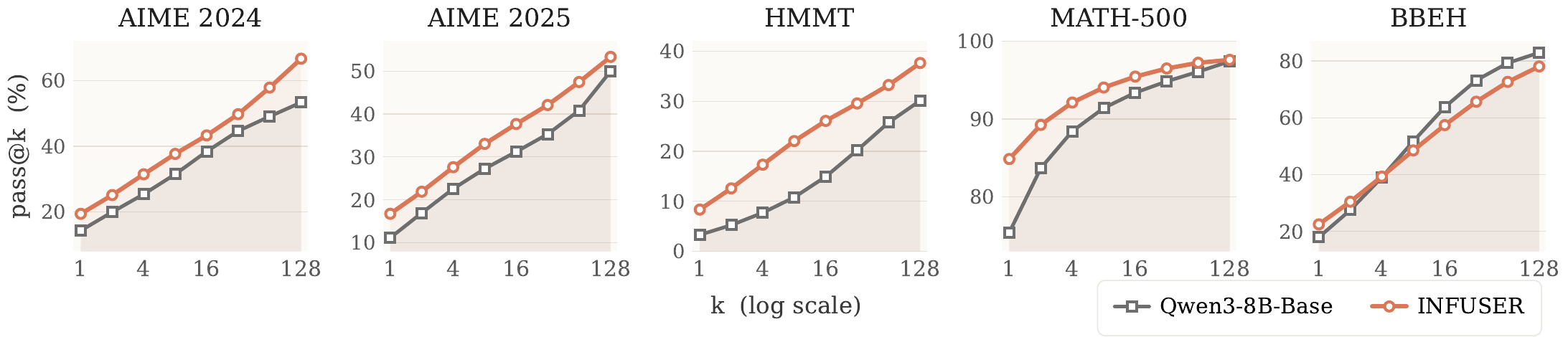
Pass@k results test whether INFUSER merely sharpens its most likely answer or broadens the support of correct reasoning paths. On several math benchmarks, INFUSER remains above the base model across many sampled attempts. This indicates that the model is not only getting better at selecting one lucky answer. Its sampled reasoning distribution has improved.
8. Conclusion
INFUSER reframes self-evolution as influence-guided curriculum learning. The generator is rewarded for examples whose optimizer-aware gradient direction helps the solver on the dev-set. The solver trains on those examples. Because both roles evolve together, the system can turn unstructured documents into a moving curriculum matched to the current model.
The broader lesson: self-generated data should be judged by training utility, not by surface difficulty alone.
Citation
@misc{chen2026infuser,
title={INFUSER: Influence-Guided Self-Evolution Improves Reasoning},
author={Siyu Chen and Miao Lu and Beining Wu and Heejune Sheen and Fengzhuo Zhang and Shuangning Li and Zhiyuan Li and Jose Blanchet and Tianhao Wang and Zhuoran Yang},
year={2026},
eprint={2606.09052},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2606.09052}
}